
When you fine-tune an LLM, you’re essentially giving a pre-trained model a specialized education using your own internal data. This process teaches the model your company's unique language, your specific workflows, and the nuanced knowledge that defines your business. It’s how you transform a generalist AI into an in-house expert, unlocking a serious competitive edge by enabling it to handle tasks with a level of accuracy and context that generic models just can't touch.
Key Takeaways
- Specialized Expertise: Fine-tuning transforms a generalist LLM into a specialist by training it on your unique internal data.
- Competitive Advantage: This process creates a bespoke AI asset that competitors cannot replicate because they don't have your data.
- Improved Performance: A fine-tuned model delivers higher accuracy and contextual relevance for business-specific tasks compared to off-the-shelf models.
Why Fine-Tuning Is Your Next Competitive Advantage
Out-of-the-box LLMs are impressive, but they don't know your business. They haven't read your support tickets, analyzed your sales calls, or studied your technical docs. Fine-tuning closes that knowledge gap, turning all that internal information from a passive asset into a powerful, active tool that drives real results.
Think of it like this: you can hire a generalist, or you can train an expert who knows your operations inside and out. The real opportunity here is turning your domain-specific knowledge into better efficiency and happier customers.
Moving Beyond Generic AI Responses
Practical Example:
Imagine a B2B SaaS company using a generic chatbot for customer support. When customers ask complex, product-specific questions, the bot fumbles, giving vague answers or escalating the ticket. This leads to a frustrating 40% escalation rate to human agents, bogging down the support team and driving up costs.
Now, picture that same company fine-tuning a model on its own knowledge base, past support tickets, and developer documentation. The new chatbot understands the company's technical terminology and common troubleshooting flows.
The fine-tuned bot can now resolve complex queries on the first try. The result? A massive drop in ticket escalations, faster resolution times, and a measurable jump in customer satisfaction. That's a clear, tangible return on investment.
Identifying High-Impact Opportunities
Impact Opportunity:
This same principle applies everywhere in the business:
- Sales Enablement: Train a model on your sales playbooks and call recordings, and it can generate hyper-personalized outreach that gets replies, directly increasing lead conversion rates.
- Code Generation: Fine-tune a model on your internal codebase, and it can write and debug code that follows your team's standards, accelerating development cycles and reducing bugs.
- Marketing Content: Feed a model your top-performing content, and it will learn to generate new copy that consistently nails your brand's voice and tone, improving campaign performance.
Fine-tuning is a versatile strategy, but it's not the only way to customize an LLM. Different business goals call for different approaches, each with its own trade-offs in terms of effort, cost, and complexity.
To help you decide what's right for your team, here’s a quick breakdown of the most common methods.
LLM Customization Methods At A Glance
| Method | Core Concept | Best For | Effort/Cost | Example Use Case |
|---|---|---|---|---|
| Prompt Engineering | Guiding the LLM with detailed instructions in the prompt. | Quick, task-specific adjustments without model changes. | Low | Creating a chatbot persona for a single conversation. |
| RAG | Providing the LLM with external knowledge at query time. | Answering questions based on a large, changing knowledge base. | Medium | A customer support bot that pulls answers from a live FAQ document. |
| Fine-Tuning | Updating the model's internal weights with your own data. | Teaching the model a new skill, style, or specialized domain. | High | A model that writes code in a proprietary programming language. |
| Pre-training | Training a model from scratch on a massive, custom dataset. | Creating a foundational model for a brand new domain (e.g., medicine). | Very High | Building a specialized legal LLM trained only on case law. |
Ultimately, the best method depends entirely on your specific goals. For many businesses looking to embed deep, proprietary expertise into their AI tools, fine-tuning hits the sweet spot between impact and feasibility.
The Proof Is in the Performance
The benefits of fine-tuning aren't just talk. Research consistently shows that smaller, specialized models can run circles around larger, general ones on specific tasks.
Practical Example:
A great example comes from a study by Databricks. They found that fine-tuning the Llama 3.1 8B model on their internal code resulted in a 1.4x improvement in acceptance rate compared to the much larger GPT-4o. Not only that, but the fine-tuned model also delivered a 2x reduction in inference latency, making it both smarter and faster for their specific needs.
This proves a crucial point: you don't always need the biggest model on the block. You need the smartest one for your problems. Fine-tuning is how you build that specialized intelligence and create a real, defensible advantage that competitors can't easily copy.
A Practical Pipeline For Fine-Tuning Success
Trying to fine-tune an LLM on your own data without a clear plan is a recipe for frustration. It's not a single task you can just knock out; it's a structured process that requires a real workflow. Thinking of it as a multi-stage pipeline helps everyone—from growth leaders to ML engineers—get on the same page, manage resources, and actually deliver something valuable.
This whole process is about turning your raw, internal data into a fine-tuned model that gives you a genuine competitive edge.
As you can see, it's a clear path from what you already have—your data—to building specialized intelligence that puts you ahead of the pack.
Scoping And ROI Analysis
Before a single line of code gets written, you have to define what "success" actually means in business terms. This is where you connect the tech project to a real, measurable outcome. Skip this, and you risk building a technically slick model that doesn't actually do anything for the bottom line.
Practical Example:
A marketing agency struggles to write high-converting email campaigns that stay consistent across dozens of clients. Their goal might be to fine-tune a model on their all-time best-performing emails to achieve a 25% increase in click-through rates for new campaigns. That’s specific, measurable, and clearly valuable.
The most critical part of any fine-tuning project is this first step. A well-defined scope with a clear ROI target is your North Star. It guides every technical decision you make down the line and ensures you’re solving a real business problem.
Data Collection And Preparation
Your model is only as good as the data you feed it. This is where you gather all that valuable proprietary info and start cleaning it up. If your data is messy, inconsistent, or just plain irrelevant, you'll end up with a garbage model, no matter how fancy your fine-tuning techniques are.
Practical Example:
A manufacturing firm wants to predict equipment failures. Their internal data might look something like this:
- Maintenance Logs: Detailed records of every repair, part replacement, and service call.
- Sensor Readings: Streams of real-time data on temperature, vibration, and pressure.
- Technician Notes: Unstructured, free-text notes where techs describe what they saw and did.
The prep work here means standardizing all the date formats, fixing typos in the technician notes, and correctly matching sensor data spikes to specific maintenance events. High-quality, clean data is the bedrock of this entire pipeline.
Base Model Selection
The good news is you don't have to build a new LLM from scratch. The next step is picking a pre-trained base model to build upon. This decision is always a balancing act between performance, cost, and what the model is naturally good at. You've got great open-source options like Llama 3, Mistral, and Gemma, and each has its own quirks and strengths.
That manufacturing firm, for example, might go for a smaller, faster model if they need real-time alerts on the factory floor. The marketing agency, on the other hand, would probably pick a larger model known for its creative flair to generate that persuasive email copy. The trick is to match the model’s architecture to the job you need it to do.
Choosing A Fine-Tuning Strategy
You've got your clean data and your base model. Now you have to decide how you’re going to fine-tune it. There are two main paths, and they represent a classic trade-off between peak performance and the resources you'll burn.
- Full Fine-Tuning: This approach updates every single parameter in the model. It's computationally intensive, but it can deliver the best results because the model is learning deeply from your data.
- Parameter-Efficient Fine-Tuning (PEFT): This is a more efficient approach. Techniques like LoRA (Low-Rank Adaptation) freeze most of the model's parameters and only train a small, targeted subset. This slashes the memory and compute power needed, making fine-tuning far more accessible.
For most businesses, PEFT is the way to go. It hits that sweet spot of significant performance gains without needing a server room full of GPUs.
Training And Execution
This is where the process comes to life. Your meticulously prepared dataset gets fed to the base model, and the training process kicks off. The goal is to adjust the model's parameters to make it an expert on your specific task. This involves tweaking hyperparameters like the learning rate and deciding how many times to show the model your data (training epochs).
This whole idea has taken off globally, with more and more companies realizing that fine-tuning is a core capability for staying competitive. Platforms like Hugging Face's AutoTrain and OpenAI's API have made it easier than ever for teams to customize models. The strategies have matured, and parameter-efficient methods like LoRA have become a go-to for balancing cost with performance. You can find more details on this seven-stage framework in recent research.
Evaluation And Benchmarking
Once training is done, you have to test the model. You test it against a "holdout" dataset—a slice of your data that the model has never seen before. This shows you how it performs on new, real-world examples.
The marketing agency would have its new model generate copy for a live campaign and compare the click-through rate against a control group. The manufacturing firm would feed it fresh sensor data to see if it correctly predicts which machines are about to fail. You need a mix of hard numbers (like accuracy) and qualitative feedback from your actual domain experts to know if you've succeeded.
Deployment And Monitoring
A great model sitting on a laptop is useless. A great model integrated into your business workflows is where the value is. Deployment means getting your fine-tuned LLM into production, whether that's through an internal API, a chatbot, or some other application your team uses.
But the work doesn't stop there. Once it's live, you have to monitor it. Over time, real-world data patterns change, and your model's performance can degrade—a phenomenon known as model drift. By continuously tracking key business metrics, you can ensure the model stays effective and keeps delivering the ROI you planned for from day one. This pipeline isn't a one-and-done project; it's a cycle of continuous improvement.
With your data prepped and goals defined, you’re at a fork in the road. The next two decisions—which base model to use and how to tune it—are where the technical rubber meets the strategic road. These choices will make or break your project's performance, budget, and timeline.
Before you even think about tuning, you have to pick your starting player. Getting a handle on the current top LLM models is non-negotiable. This isn’t just about chasing the highest benchmark scores; it's about finding a model whose architecture and inherent strengths actually match what you’re trying to build.
Picking The Right Open-Source Model
Thankfully, the open-source world has given us an incredible lineup of powerful base models. Each one brings something different to the table, and your job is to find the right fit. Let's look at the big three right now: Llama 3, Mistral, and Gemma.
- Llama 3 Models: Built by Meta, these are fantastic all-rounders. They're known for being great at reasoning and following complex, multi-step instructions. If you're building a chatbot that needs to handle nuanced customer support flows, Llama 3 is a rock-solid starting point.
- Mistral Models: These models are the efficiency champions. They deliver performance that rivals much bigger models but with a fraction of the computational footprint. A team building a real-time sales email summarizer on a tight budget would be smart to look at Mistral first.
- Gemma Models: As Google's contribution, Gemma models are built from the ground up with responsible AI in mind. Their lightweight versions are a godsend for apps that need to run on less beefy hardware without sacrificing quality.
The trick is to match the model’s DNA to your business goal. A model built for creative writing is a different beast than one designed for generating code. Nail this choice upfront, and you'll save yourself a world of pain and wasted resources down the line.
Key Takeaways
- Match the Model to the Task: Select a base model (e.g., Llama 3 for reasoning, Mistral for efficiency) whose inherent strengths align with your specific business objective.
- PEFT is the Default Choice: For most businesses, Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA offer the best balance of performance, cost, and speed.
- Trade-offs are Key: Your choice of model and tuning strategy is a strategic decision balancing performance gains against computational cost and development time.
Full Fine-Tune vs. Parameter-Efficient Methods (PEFT)
Once you’ve picked your model, you have to decide how you're going to teach it your company's secret sauce. This decision really comes down to two paths, and they have wildly different implications for your budget and timeline.
A Full Fine-Tune means you’re updating every single parameter in the entire model. It’s the most thorough approach, allowing the model to learn your data inside and out. This can lead to the absolute best performance, but it comes at a staggering cost. You need a ton of computational power, massive amounts of VRAM, and a lot of time, which puts it out of reach for most companies.
Then there’s Parameter-Efficient Fine-Tuning (PEFT). This is the smarter, more accessible path. Techniques like LoRA (Low-Rank Adaptation) freeze most of the original model and just inject a few small, trainable layers. You end up updating a tiny fraction of the total parameters, which slashes your GPU memory and compute needs by up to 90%.
Comparing Fine-Tuning Strategies: Cost vs. Performance
Deciding which fine-tuning strategy to use can feel overwhelming. This table breaks down the key differences to help your team align on the best path forward based on your specific budget, timeline, and performance targets.
| Strategy | Computational Cost | Performance Gain | Best For | Example Scenario |
|---|---|---|---|---|
| Full Fine-Tuning | Extremely High | Highest Potential | Mission-critical tasks where maximum accuracy is non-negotiable and budget is no object. | A specialized medical diagnostic AI that needs to be near-perfect. |
| LoRA (PEFT) | Low | High | Most business use cases; achieving high performance on a reasonable budget. | A customer support chatbot that needs to understand company-specific jargon. |
| Instruction Tuning | Low to Medium | Medium | Teaching a model to follow specific formats or commands without deep domain adaptation. | An internal tool that generates reports in a consistent, predefined structure. |
| Prompt Engineering | Very Low | Low to Medium | Quick wins and testing concepts without any model training. | Creating a simple marketing copy generator for social media posts. |
Ultimately, for most teams, a PEFT method like LoRA provides the ideal balance. It allows you to get the domain-specific performance you need without having to build a supercomputer in your server room.
LoRA In Action: A Real-World Scenario
Practical Example:
Imagine a law firm wants to train an LLM to summarize dense legal contracts, using their firm’s specific language and formatting. A full fine-tune is off the table—it would be way too expensive and take forever.
This is where LoRA shines. By using a PEFT approach, they can fine-tune a model like Llama 3 on their massive archive of contracts using just a single, mid-tier GPU. The end result? A highly specialized model that nails its one job perfectly, all without the firm needing to break the bank on hardware.
This isn't just a hunch; the data backs it up. A study from the National Institutes of Health showed that for text classification, a basic Supervised Fine-Tuning (SFT) approach boosted F1-scores for Llama3 by a massive 55% and for Mistral2 by 33%. This shows how effective even simple tuning can be.
For the engineers on your team, getting started with LoRA using a library like Hugging Face transformers is surprisingly simple. Here’s a quick look at what the configuration involves:
from peft import LoraConfig, get_peft_model
# Define LoRA configuration
lora_config = LoraConfig(
r=16, # The rank of the update matrices
lora_alpha=32, # The scaling factor
target_modules=["q_proj", "v_proj"], # Apply LoRA to query and value projections
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Apply LoRA to the base model
peft_model = get_peft_model(base_model, lora_config)
That’s pretty much it. This small block of code is the difference between a cripplingly expensive project and an efficient, high-impact one. Making smart technical choices like this is what a successful AI enablement strategy is all about—delivering real value, faster and cheaper.
Evaluating Performance And Measuring Real-World Impact
You’ve put in the hard yards—prepping data, training your model, and running countless experiments. Now for the moment of truth. Did it actually work?
Answering that question means moving past abstract technical scores and focusing on what really matters to the business. The goal here is to prove, with undeniable evidence, that your fine-tuned model is delivering real-world value.
The best way to get a clean read on this is with a holdout dataset. This isn't just any data; it’s a carefully curated set of real business scenarios the model has never seen before. Testing against this unseen data is the only way to know how it will actually perform when it's live.
Combining Quantitative and Qualitative Metrics
A solid evaluation framework needs a mix of hard numbers and human judgment. If you rely on just one, you’re only getting half the story.
Quantitative metrics are your data-driven measures of success. They’re non-negotiable for tracking progress and proving ROI to leadership.
- Accuracy: What percentage of the time does the model produce the correct output?
- Response Time: How fast does it return a response? For any real-time application, latency is a critical business metric.
- Conversion Rate: If you’re generating marketing copy, does it lead to more clicks or sign-ups? This ties the model directly to revenue.
But numbers alone can't tell you about tone, relevance, or brand voice. That’s where qualitative feedback from your domain experts becomes invaluable.
True performance isn't just an accuracy score. It's a blended evaluation—quantitative business KPIs on one side, qualitative feedback from your team on the other. This ensures the model isn't just technically correct, but genuinely useful in the real world.
For instance, have your top sales reps review AI-generated outreach emails. Let them score the outputs on personalization, clarity, and persuasiveness—things a simple accuracy metric would completely miss. This human-in-the-loop validation is how you make sure the model meets the high standards of your best people.
Running A/B Tests for Direct Impact Measurement
When you need to measure real-world impact, the A/B test is the gold standard. There's no ambiguity. You pit your shiny new fine-tuned model against a control—the base model, your old system, or even a manual process.
Practical Example:
A marketing team fine-tuned an LLM to write ad copy. They could run a live campaign where:
- Group A (Control): Sees ads with copy written by human marketers.
- Group B (Test): Sees ads with copy generated by the fine-tuned LLM.
By tracking metrics like click-through rate (CTR) and cost per acquisition (CPA), they can calculate the precise lift. If Group B delivers a 15% higher CTR at a 10% lower CPA, you’ve just built an airtight business case for the project.
Monitoring for Model Drift Post-Deployment
Getting your model into production isn't the finish line. The world changes. Your customers evolve. Your business priorities shift. Over time, these changes can degrade your model's performance in a phenomenon known as model drift.
Ongoing monitoring is the only way to protect your investment. You need to keep tracking the same quantitative and qualitative metrics you established during your initial evaluation.
If you start seeing a steady decline in performance, that’s your cue. It’s a signal that the model needs a refresh with more recent data. Think of it as how teams use predictive churn modeling to get ahead of customer issues. It’s a proactive strategy to ensure your AI continues to deliver value long after launch.
Navigating Security, Compliance, And Deployment
Getting your model to perform well in a sandbox is one thing. Moving it into the real world? That’s a whole different beast. Deploying an LLM fine-tuned on proprietary data isn’t just a technical handoff—it's a massive security and compliance challenge. One wrong move could expose sensitive information, violate regulations like GDPR, or completely shatter customer trust.
You have to approach this with a security-first mindset from day one. That means thinking ahead about risks like data leakage during training, preventing the model from memorizing and spitting out confidential details, and picking a deployment architecture that matches your company's risk tolerance.
Key Takeaways
- Security First: Prioritize data security from the start by using anonymization and considering techniques like differential privacy to prevent data leakage.
- Choose the Right Home: Select a deployment model (on-premise, VPC, or secure API) that aligns with your data sensitivity and regulatory requirements.
- Govern Proactively: Establish a strong AI security governance framework to maintain compliance with regulations like GDPR and HIPAA, ensuring long-term trust and legal standing.
Protecting Your Data During And After Training
The single biggest risk when fine-tuning on your own data is unintentional exposure. It’s surprisingly easy for a model to memorize and then regurgitate personally identifiable information (PII) or confidential business secrets it saw during training.
Solid data governance is your best defense here. Your first line of defense is data anonymization and pseudonymization. Before any data gets near the model, you need to scrub or replace PII—names, addresses, social security numbers—with placeholder tokens. This lets the model learn the patterns without absorbing the sensitive specifics.
Another powerful technique is differential privacy, which essentially adds calculated statistical noise to the training data. This makes it almost impossible for an attacker to figure out if any specific person's data was used, giving you a mathematical guarantee of privacy.
Choosing The Right Deployment Pattern
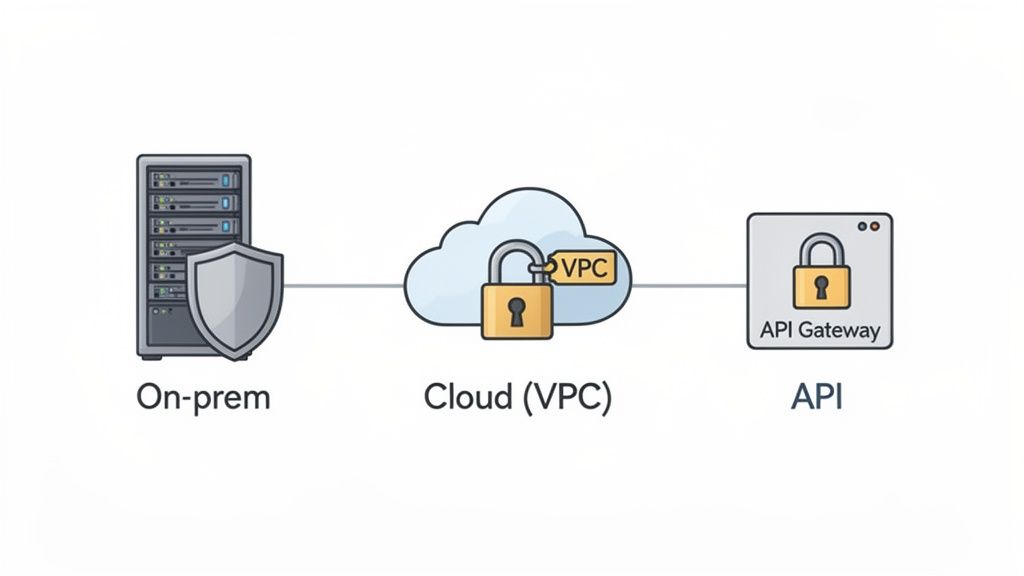
Where you host your model has a direct and significant impact on its security. There are three main ways to go, each with its own trade-offs in control and protection. Your choice really depends on how sensitive your data is and what your industry’s regulations demand.
- On-Premise Deployment: Hosting the model on your own servers gives you absolute control. All your data stays locked down within your own walls, which is often a non-negotiable for companies with highly sensitive IP or strict compliance mandates.
- Virtual Private Cloud (VPC): Think of a VPC as your own private, isolated corner of a public cloud. It strikes a great balance between security and scalability, giving you tight control over network access while still letting you take advantage of cloud infrastructure.
- Secure API Endpoint: Using a trusted third-party service to host the model is the simplest path. But this route requires you to be incredibly diligent in vetting the provider. You need to scrutinize their security protocols, data handling policies, and compliance certifications.
Impact Opportunity
For companies in regulated industries like healthcare or finance, a hybrid approach using a VPC is often the sweet spot. It isolates sensitive data and model interactions from the public internet, satisfying compliance requirements for standards like HIPAA and GDPR, while still providing the operational benefits of the cloud.
Maintaining Compliance In Regulated Industries
If you operate under regulations like GDPR in Europe or HIPAA in the U.S., the stakes are incredibly high. Compliance isn’t a nice-to-have; it's a legal requirement with steep penalties for getting it wrong.
A core part of this is building a clear governance framework that dictates how data is used, stored, and protected through the entire AI lifecycle. This means implementing tight access controls, keeping detailed audit trails, and running regular security assessments to stay on top of things. To successfully deploy fine-tuned LLMs with proprietary data, establishing clear governance policies is paramount. For a comprehensive guide, refer to insights on AI Security Governance.
By baking security and compliance into your deployment strategy from the very beginning, you can innovate with confidence, knowing that your most valuable asset—your data—is protected.
So, Where Do You Go From Here?
You’ve seen the full picture now, from scoping out high-ROI projects to wrestling with the nitty-gritty of secure deployment. Treating this as just another tech project is a mistake. Fine-tuning a large language model on your own data is a serious strategic move.
The core idea is simple: your internal data is an asset gathering dust. Fine-tuning is how you put it to work. It’s what transforms a generic AI into a specialist that speaks your company’s language, understands your customers, and knows your market inside and out.
Your Pre-Flight Checklist
Before you dive in, let's run through the big questions. Getting these right upfront will save you a world of headaches later.
- Define the Problem: Do you have a specific, measurable business problem you're trying to solve? Can you prove the ROI? Don't start without a clear "why."
- Check Your Data: Is your proprietary data actually ready? Is it collected, cleaned, and prepped for training? Remember, garbage in, garbage out. Quality is everything.
- Align the Team: Are your growth, engineering, and ops leaders all on the same page? Everyone needs to agree on the goals, metrics, and resources needed to make this happen.
- Pick Your Tools: Have you chosen a base model and a fine-tuning strategy (like LoRA) that actually fits your performance needs and budget?
- Lock It Down: How will you protect sensitive data and stay compliant? You need a concrete plan before you start, not after.
Key Takeaways
- Strategy, Not Just Tech: Fine-tuning is a strategic business decision that requires clear goals, clean data, and cross-functional alignment to succeed.
- Data is the Moat: Your proprietary data is the ultimate competitive advantage; fine-tuning is the process that weaponizes it.
- Plan Before You Build: A successful project depends on having a concrete plan for ROI, data quality, tool selection, and security before any technical work begins.
The Real Prize
Ultimately, this is about building a defensible moat around your business. Sure, your competitors can use the same off-the-shelf AI tools. But they don't have your data. By fine-tuning, you’re creating a bespoke, high-performance asset that is 100% yours.
Fine-Tuning FAQs: Your Questions, Answered
Let's tackle some of the most common questions that pop up when teams start planning a fine-tuning project. Getting these right from the beginning can save you a ton of headaches down the road.
How Much Data Do I Actually Need?
This is the classic "it depends" question, but here are some solid guideposts. The answer hinges entirely on the complexity of your goal.
If you're aiming for a narrow, well-defined task—like teaching an LLM to master your brand's specific tone of voice or classify customer support tickets into five categories—you can often get incredible results with just a few hundred to a few thousand high-quality examples. We’ve seen style adaptation work wonders with as few as 500 good examples.
On the other hand, if you're trying to teach the model complex, multi-step instruction-following behaviors, you'll need a much larger dataset, potentially in the tens of thousands.
The single most important thing to remember is that data quality will always trump quantity. A small, pristine, and perfectly labeled dataset is infinitely more valuable than a massive, noisy one. Your highest-use activity isn't just collecting data; it's curating it.
What’s the Real Difference Between Fine-Tuning and RAG?
It's easy to get these two confused, but they solve different problems.
Think of fine-tuning as teaching the model a new skill or fundamentally changing its "personality." You're baking new knowledge or behaviors directly into the model's parameters. It's about how the model thinks and responds.
Retrieval-Augmented Generation (RAG) is more like giving the model an open-book test. You're providing it with external, up-to-the-minute information at the exact moment it's needed (at query time), without actually changing the model itself. It's about what information the model has access to.
They aren't competitors; they're collaborators. Some of the most powerful systems use a fine-tuned model on top of a RAG pipeline. This gives you the best of both worlds: a model with specialized skills that can also pull from a constantly updated knowledge base.
What’s a Realistic Budget for a Fine-Tuning Project?
Costs can swing wildly, from a few hundred dollars for a quick experiment to tens of thousands for a large-scale, production-grade model.
The main levers that drive your costs are:
- Base Model Size: Bigger models cost more to train.
- Data Volume: More data means more GPU time.
- Tuning Method: Full fine-tuning is expensive. PEFT methods like LoRA are dramatically cheaper.
- GPU Compute Time: This is your direct cloud bill.
Practical Example: A pilot project using LoRA on a solid mid-sized model like Llama 3 8B can often be done for under $1,000 in pure compute costs. That number doesn't include the human-hours for data prep, but it makes the initial exploration of fine-tuning highly accessible for most teams.
Ready to unlock the value in your proprietary data? Prometheus Agency is an AI enablement partner that helps growth leaders build durable revenue systems. Start with a complimentary Growth Audit and AI strategy session to build your roadmap.
